Reliability Isn't a Vendor You Pick. It's an Architecture You Own.
This fortnight a government switched off the most capable AI on Earth in hours, the market crowned its 'most reliable' vendor, and Nadella called AI 'token capital.' Three stories, one category error — and the architecture that fixes it.
Three things happened in the same fortnight of June 2026. The tech press filed them in three different folders. They are one story, and the story has a punchline most of the industry just got backwards.
One: on June 12 at 5:21 PM ET, the US Commerce Department ordered Anthropic to suspend Claude Fable 5 and Mythos 5 — the most capable models ever shipped to a public API — for every foreign national on Earth. There is no passport scanner on a REST endpoint, so within hours the models went dark for everyone, worldwide. (I wrote the personal version of that night here: At 5:21 PM, the Smartest AI on Earth Went Dark.)
Two: on June 14, Satya Nadella published an essay calling AI a company's "token capital" — the AI capability you build and own, compounding alongside human capital. His line: "You can never offload your learning."
Three: Ramp's payment data, surfaced June 13, showed Anthropic overtaking OpenAI in US business adoption — 34.4% to 32.3%, with roughly 73% of all first-time enterprise AI spend now going to Anthropic. The reason analysts keep citing isn't benchmark scores. It's reliability.
Hold those three side by side and a single fact falls out of them.
Capability is now revocable infrastructure
The provider that enterprises just crowned for reliability is the exact same one whose flagship a government switched off on June 12 — and whose API went globally dark on June 2 in an unrelated outage. Microsoft 365 Copilot went down for hours on June 11 and again around June 15. None of those events were bugs you could patch. One was a memo. One was a broken auth deploy. All of them stopped real production work.
So here is the uncomfortable reclassification: the most capable intelligence in your stack is no longer a fixed input. It is a centrally administered service that a party who is not you can revoke — by directive, by outage, by pricing change — on a clock you do not control.
That reframes Nadella perfectly. He's right that AI is now capital. He's just early to the punchline: token capital you can't run yourself isn't capital. It's a lease — and June 12 proved the lease has a kill clause measured in hours.
The category error the whole market just made
Now the part the market cannot see, because it just voted the other way.
Enterprises made reliability their number-one buying criterion. Good. Then they tried to satisfy it by switching vendors — moving spend from the less reliable provider to the more reliable one.
That is a category error.
Reliability was never a property you can purchase from a provider, any more than security is. The "most reliable" vendor in the Ramp report is one export-control letter away from dark. Choosing a more reliable single supplier to fix a single point of failure just gives you a nicer single point of failure. The buyers got the question exactly right and the answer exactly backwards.
The reliability of a distributed system has never lived in any one component. It lives in the connections between them — the fallbacks, the circuit breakers, the graceful degradation, the ability to lose any single node and keep serving. Site reliability engineering learned this two decades ago with servers. We are relearning it now, one layer up, with frontier models as the component that fails. (The deeper failure mode — reliability under accumulated state — I covered in The Pass^k Wall.)

Reliability is not a vendor you select. It is an architecture you own.
Treat the frontier model as an untrusted oracle
The design move is to stop treating the frontier model as a dependency and start treating it as what June 12 proved it to be: an untrusted oracle. Brilliant, worth every token, and one memo from gone. Architect every critical loop to assume it will vanish:
- Owned or portable inference — a fallback provider, a prior-generation model, or a local open-weight model that no directive can switch off.
- Graceful degradation — when the frontier drops, the workflow gets slower or simpler; it does not stop.
- Portable context — the accumulated "company veteran" knowledge of your agents lives in your memory layer, so it survives any provider going dark.
This isn't pessimism about AI. It's the opposite. It's the discipline that lets you bet your business on AI because you've stopped betting it on any single supplier of AI. That discipline has a name: AI Reliability Engineering. June 2026 just made it the difference between a company that ships through a blackout and one that waits for the lights to come back.
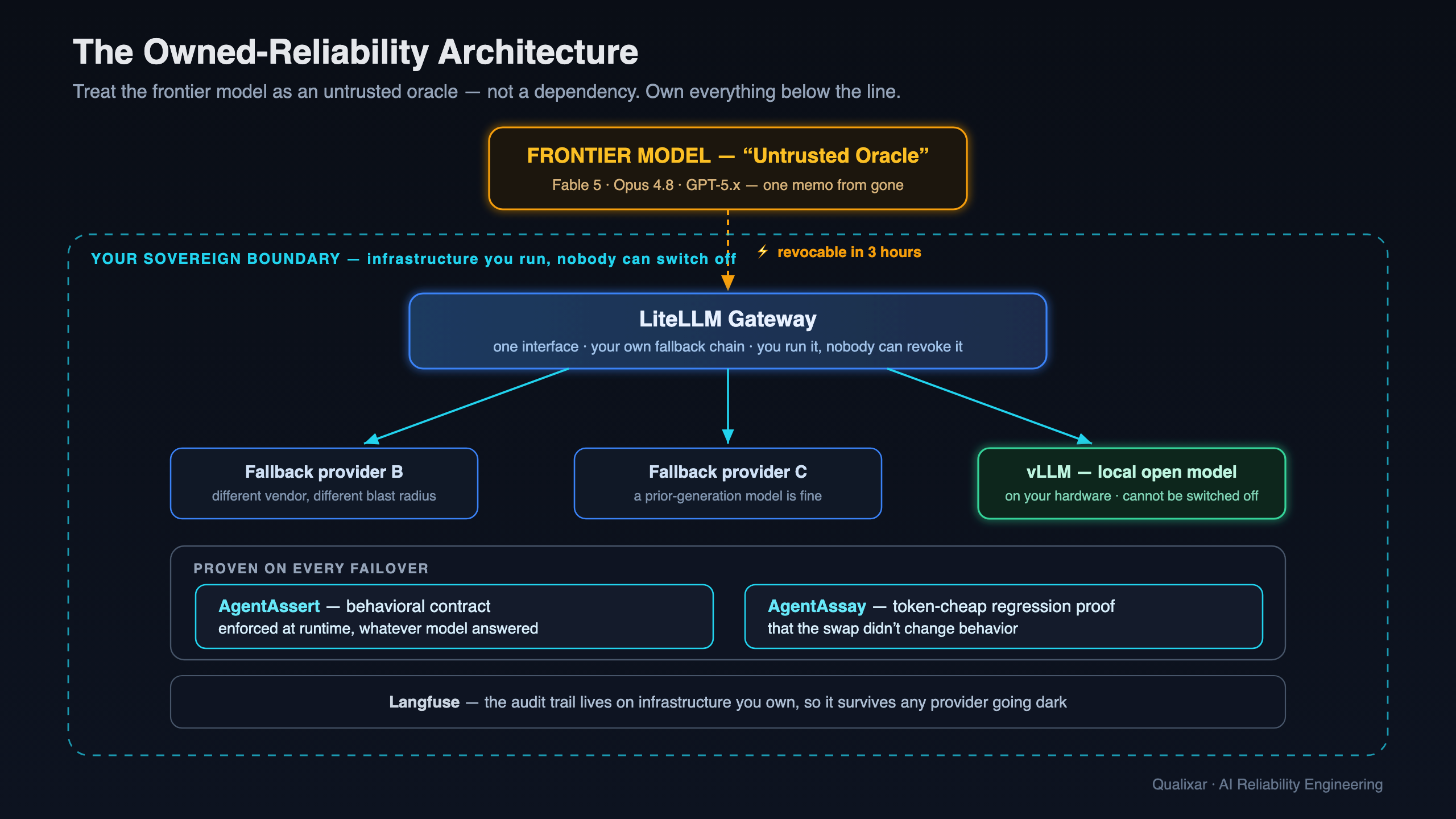
The stack that makes it real
You can build this today, mostly with open source.
Own the failover. BerriAI/litellm (~50.8k ⭐) is a self-hostable gateway: one interface in front of 100+ providers, with a fallback chain you define. Primary 500s or breaches a latency budget, and the request routes onward automatically. You run it; nobody can revoke it.
Own the cold spare. vllm-project/vllm (~83k ⭐) serves open-weight models on your own hardware with an OpenAI-compatible endpoint. It's the bottom of the chain — the difference between degraded and down when every hosted provider is dark. (On the economics of routing between these tiers, see the Fable 5 burn-rate piece.)
Own the audit trail. langfuse/langfuse (~29k ⭐, MIT, self-hostable) keeps your traces, sessions, and scores on infrastructure you control — so the record survives the vendor that can go dark.
There's a problem this stack creates, though, and most teams never test for it: when you fail over from a frontier model to a fallback, does your agent still behave the same? A cheaper or older model that silently changes one decision isn't a safety net. It's a hidden second failure.
That's the gap we build for at Qualixar.
AgentAssert turns "the agent behaves" into a contract with a number on it. You write what your agent must and must not do as a YAML spec, and it's enforced at runtime, regardless of which model answered — so a failover to a local model still honors the same behavioral contract. It adds drift detection (Jensen-Shannon divergence) and probabilistic (p, δ, k)-satisfaction bounds. (arXiv:2602.22302)
AgentAssay makes the failover auditable. Testing every model swap is normally too expensive to bother with — hundreds of trials burned to check for one regression. AgentAssay uses behavioral fingerprinting (what the agent did, not what it said) and adaptive budget allocation to deliver the same statistical confidence at a fraction of the token cost. Every time you add or swap a provider, it tells you — cheaply — whether behavior held. (arXiv:2603.02601)
Own the failover. Enforce the contract on whatever model answers. Prove the swap didn't break anything. That's the architecture.
Three things to do before your next provider goes dark
- Put one fallback provider behind your most critical agent this week. Stand up LiteLLM, define a two-link chain, force a failure in staging, and watch it route. The first time your agent rides through a simulated outage without stopping, "untrusted oracle" stops being a slogan.
- Stand up one open-weight model as a cold spare. It doesn't have to be your primary. It has to exist, so "every hosted provider is dark" is a degraded mode, not an outage.
- Run a behavioral regression before you trust any fallback. Wrap the agent in an AgentAssert contract, fingerprint it with AgentAssay on your primary, re-run on the fallback. If the fingerprints diverge, your safety net was quietly changing decisions — better found on a Tuesday than during the next directive.
The money is moving as if this dependency is permanent and priceless — Anthropic toward a Q4 IPO near a trillion dollars, OpenAI racing the same window, Amazon's custom silicon past a $20B run-rate underneath it all. (Three months ago Elon Musk called Anthropic evil; last Tuesday he effectively became their landlord — compute is the moat, models are tenants.) And on June 16, xAI paid the ultimate price of dependency: SpaceX announced a $60 billion all-stock deal to buy Cursor outright — after Anthropic had cut off xAI's staff from using Claude through that very tool. A frontier provider revoked a competitor's access, not for safety but for market position, and the competitor's answer was a $60B acquisition. The valuations price in zero revocation risk. June 12 and June 16 put two numbers on that risk: revocable in hours, and $60 billion to escape.
"Everything fails, all the time." — Werner Vogels, CTO, Amazon
He said that about cloud servers, and it founded modern reliability engineering. Frontier models are now infrastructure — more capable, more central, and more revocable than any server he was describing. The teams that internalize his sentence will build the failover before they need it. The rest will learn it the way the industry always does: at 5:21 PM on a day they didn't pick.
Outside the lab
I spend my weeks arguing you should never depend, without a fallback, on intelligence you don't control. This week I also released something from the other side of that idea — a short film, on my personal channel, about the kind of intelligence you can't outsource at all. It's called The Reaching, and it's about what AI will never learn. Nadella's line — "you can never offload your learning" — is a sentence about enterprise strategy. The film is the same sentence, about a life.
→ 🎬 Watch The Reaching · 📝 Read the essay
This piece is the analytical companion to Issue #8 of the AI Reliability Engineering newsletter. Research verified via cross-model checks (WebSearch + Perplexity + Grok) against primary sources (Reuters, Anthropic, Ramp, Nadella's essay).