I shipped 7 versions of my product in one night with Fable 5. It cost me 5 hours in 35 minutes.
What the burn-rate reality of Claude Fable 5 tells us about AI model selection — and the routing discipline that fixes it.
I pointed Claude Fable 5 at my codebase on a Tuesday night and watched it ship seven releases of my product before I'd finished a cup of chai. Thirty-five minutes in, my Claude Max usage window was empty. Five hours of quota, gone. I hadn't really done anything. Fable had.
That sentence is the whole story, and it's the part nobody writing about the Fable 5 launch is telling you, because you only see it if you run the thing on real work instead of reviewing the press release. So here's what happened, what it actually cost, and the fix I wish I'd had running before I started: knowing which model to point at which job.
What it actually did
I wasn't testing Fable. I was shipping. The product is SuperLocalMemory, the local memory engine I build, and that night I was pushing the 3.6 line out the door. Here's the real git log, not a story I'm telling you after the fact:
06-09 21:47 v3.6.4 memory-integrity & reliability hardening
06-09 22:25 fix stop eager-importing torch in the dep check <- a real bug, caught mid-run
06-09 22:30 v3.6.5 released, 43 minutes after 3.6.4
06-10 07:40 v3.6.6 recall precision & memory hygiene
06-10 09:24 v3.6.7 embeds HTTP MCP transport (in progress)
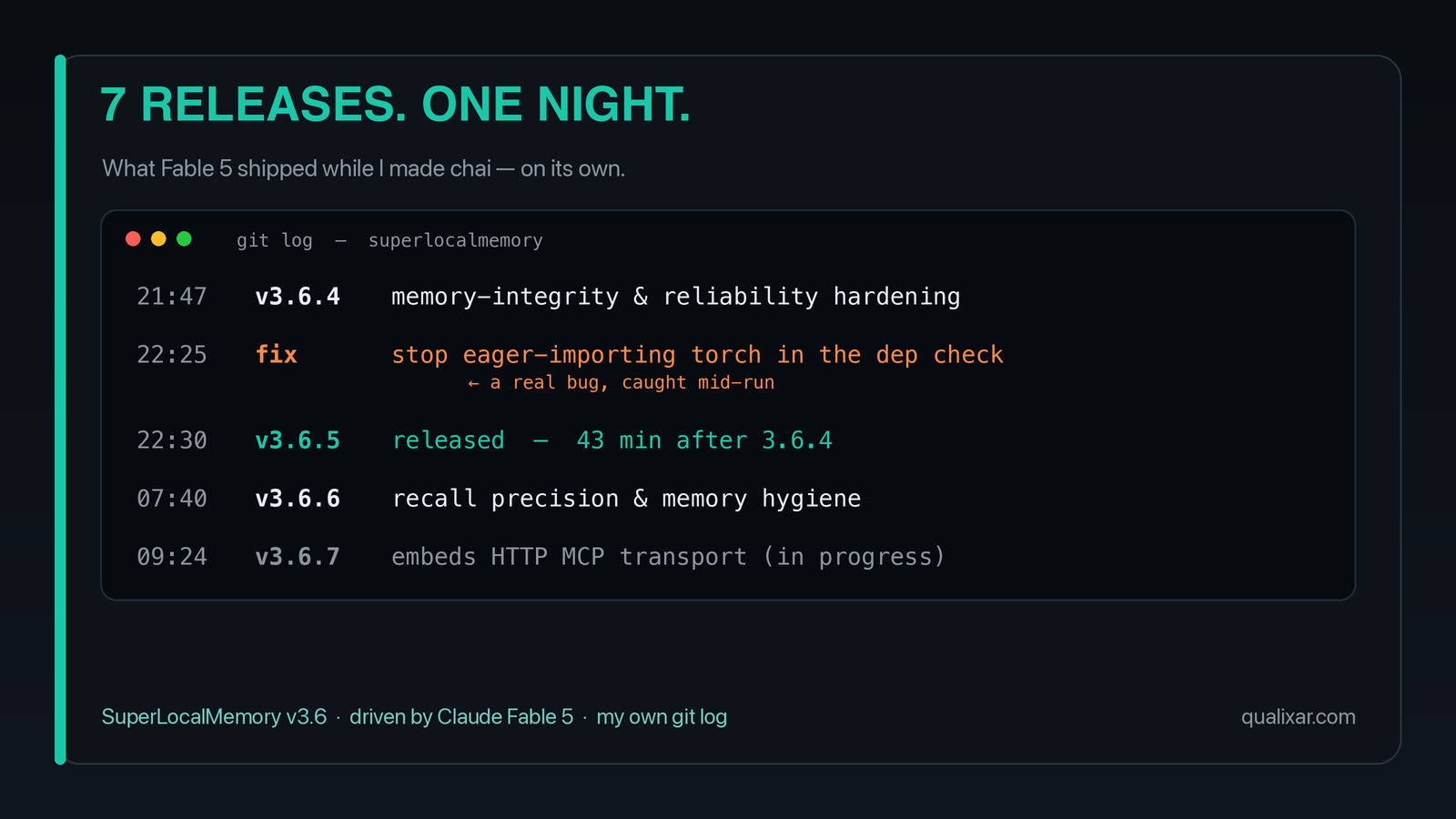
Seven releases in the 3.6 line, one after another, v3.6.0 through v3.6.6. The jump from 3.6.4 to 3.6.5 took 43 minutes, and in the gap it caught a real bug: the dependency check was eager-importing torch into every process, the kind of thing that quietly bloats memory on every machine that installs you. It found it, fixed it, cut the release, moved on.
Opus 4.8 doesn't behave like this for me. Ask Opus a question and it answers the question. It's brilliant, careful, and it waits for you. Fable doesn't wait. You hand it a goal and it spins up a workflow, decomposes the thing, and starts executing step by step, like it quietly hired a team while you weren't looking. The first time you watch it, it's genuinely thrilling. The product builds itself in front of you.
Then the bill arrives.
The cost nobody is pricing
One misconception to kill first, because if we get it wrong someone will rightly correct us: the expensive part is not that you're "running" a model the size of Fable. You aren't. Anthropic runs it. You rent it by the token. The expensive part is that Fable spends those tokens for you, fast, and the bill is a function of how much work it decides to do on its own.
Fable 5 is priced at $10 per million input tokens and $50 per million output tokens. That is exactly twice the price of Opus 4.8 ($5/$25). Now put that price tag on a model whose default instinct is to run a full agentic workflow for almost anything you ask. Every step reads context, thinks, writes, reviews itself, tries again. The meter isn't ticking, it's sprinting. That's how a five-hour window evaporates in thirty-five minutes of wall-clock time. The capability is real. So is the burn rate, and the burn rate is the line item that never makes the launch graphics.
There's a second cost most people miss. On the Max plan, Anthropic runs two limits at once: a rolling 5-hour window and a weekly cap. Opus drains that limit roughly three to five times faster than Sonnet for the same work, and Fable in workflow mode is hungrier still. They don't publish the exact numbers. You find them the way I did, by hitting the wall at 10pm.
The footnote that should be the headline
Here's the catch that made me laugh when I went back and read the announcement carefully.
Fable 5 and Mythos 5 are the same underlying model. Fable is the public one with safety classifiers; when your prompt touches cybersecurity, biology and chemistry, or model distillation, Fable doesn't answer with its full weight. It hands the request to Opus 4.8 and tells you it did. That's the safety design, and it only trips on under 5% of sessions.
But look at the benchmark table. Anthropic's own numbers show the higher of the two models' scores, and on the starred rows, the scary ones, cyber and bio, that number is Mythos 5's. The Fable 5 you can actually deploy falls back to Opus 4.8 on exactly those topics. So the chart that sells you the most powerful model in the world is, in places, scoring a model you are not allowed to run, while you pay double for the one you are. It's the menu photo. The burger in the picture is not the burger that arrives. The burger that arrives is still good. It's just Opus 4.8, which you could have bought for half the price.
The Anthropic game, said plainly
I have real respect for Anthropic's research. I also think their marketing is the sharpest in the industry, and it works by selling you the fear and then selling you the cure. The choreography this month was almost too clean. One week Anthropic warns that frontier AI is getting dangerous enough that labs should agree on a brake pedal. The next week it ships its most powerful public model, prices it at a premium, and reframes the danger itself as the feature you're paying for. TechCrunch put the timing in its headline. The fear is the funnel. The model is the conversion.
This isn't a conspiracy, it's craft, and it's worth naming because the fear narrative does something specific to buyers: it makes the biggest, most expensive model feel like the responsible default. If the frontier is this powerful and this dangerous, surely I should be on the best one. So people reach for Fable for everything, including the work a far cheaper model would do perfectly well, and then wonder why the budget is gone by lunch.
The question almost nobody asks: which model for which task
This is the lesson I actually walked away with, and it has nothing to do with Fable being good or bad. It's good. That was never the question. The question is fit, and most people right now have no working model of which model to use for which job. That single gap is quietly the most expensive thing in AI. It's the difference between a 50-dollar day and a 500-dollar day for the same output.
Two dials, not one. First, the model: Opus, Sonnet, or Haiku is which brain, and the price tiers tell you the rest ($5/$25, $3/$15, $1/$5 per million). Second, the effort level: low, medium, high, xhigh, max is not a different model, it's how hard that brain works — how many tokens it burns. The trap is treating effort like it's free. It isn't. Crank Sonnet to high and it emits a much bigger pile of thinking tokens, each billed at Sonnet's rate; because Opus is only about 1.6x Sonnet's output price, a high-effort Sonnet run can quietly cost as much as a low-effort Opus run, while being the weaker model. Effort is a dial that can erase the gap between tiers. Most people never touch it, or pin it to max and call it being thorough.
The fix: route, don't reach
The answer to Fable's burn isn't a cheaper model. It's routing. Fable burned my quota because I let the most expensive model run every step itself. The discipline, the one we call AI Reliability Engineering, is to make the expensive model the brain and let cheaper models do the legwork. Here's the ladder I run now:

| Layer | Model | Effort | Use it for |
|---|---|---|---|
| Orchestrator | Opus 4.8 | high / xhigh | Plan the work, decompose, architecture and security calls, the final judgment |
| Workhorse | Sonnet 4.6 | medium | Most implementation, refactors, long runs |
| Cheap labor | Haiku 4.5 | low | Unit tests, lint fixes, extraction, classification, file triage |
| Autonomous push | Fable 5 | — | Overnight agentic runs you genuinely want to run themselves, meter watched |
Read that as: Opus plans once and dispatches. Security scanning, where the cost of a miss is high, goes to Opus. Unit tests, which are mechanical, go to Haiku. The bulk of the coding sits on Sonnet at medium. You spend the frontier price only where frontier judgment changes the outcome. In practice this runs as one orchestrator spawning cheaper sub-agents per task, which is exactly how my SLM release should have gone: Opus driving, Haiku writing the tests, Sonnet doing the refactors, Fable reserved for the one genuinely autonomous overnight push, with the meter in view.
The irony of that night isn't lost on me. I was shipping a reliability tool, and the most powerful model on earth spent the evening teaching me a reliability lesson about itself. Don't buy the fear, and don't buy the freight train for the milk run. The skill that's about to separate the people who get value from AI from the people who just get a bill isn't prompting. It's routing: the right model, at the right effort, for the right task, on purpose.
I'm writing the full routing playbook, with the real per-task costs and the rate-limit math, in The AIRE Wire. If "which model for which job" is a question you keep guessing at, that's the newsletter to be on.
Sources: Anthropic, "Claude Fable 5 and Claude Mythos 5" (anthropic.com/news/claude-fable-5-mythos-5). TechCrunch, June 9 2026. AWS Bedrock launch post. Pricing: platform.claude.com/docs pricing. Max plan limits: Anthropic Help Center (figures unpublished; multipliers from independent telemetry). Release log: SuperLocalMemory v3.6.0–3.6.6, June 9–10 2026, my own repo. Burn-rate observation: my own Claude Max session, run firsthand.
This post is about superlocalmemory→