I Cut My Claude API Bill Without a Cloud Proxy — Here's How
A local-first way to skip repeat LLM calls, compress prompts 60–95%, and trigger your provider's own KV-cache discount — one line, open source.
Most "cut your LLM bill" tools work the same way: you point your traffic at their cloud proxy, and they cache and compress on their servers. It works. It also means your prompts — often with customer data in them — now travel through someone else's infrastructure. For a lot of teams, that trade is a non-starter.
So I built the other version: the same skip-and-shrink mechanics, running entirely on your machine, as a module on top of an open-source memory engine I've been working on for eight months. It's free, it's AGPL-3.0, and adopting it is a one-line change. Here's exactly what it does and why each part is built the way it is.
The bill has three different leaks
When you call a model repeatedly from an agent, you're losing money in three distinct ways, and they need three different fixes:
- You re-ask things you've already asked. Same prompt, same answer, full price again.
- Your prompts are bloated. Context you stuffed in "just in case" is billed token-for-token.
- You leave the provider's own discount on the table because your prefix keeps changing.
v3.6 "Optimize" handles all three — Skip, Shrink, Discount — and the design choices are where the reliability part lives.
Skip: the call that costs nothing
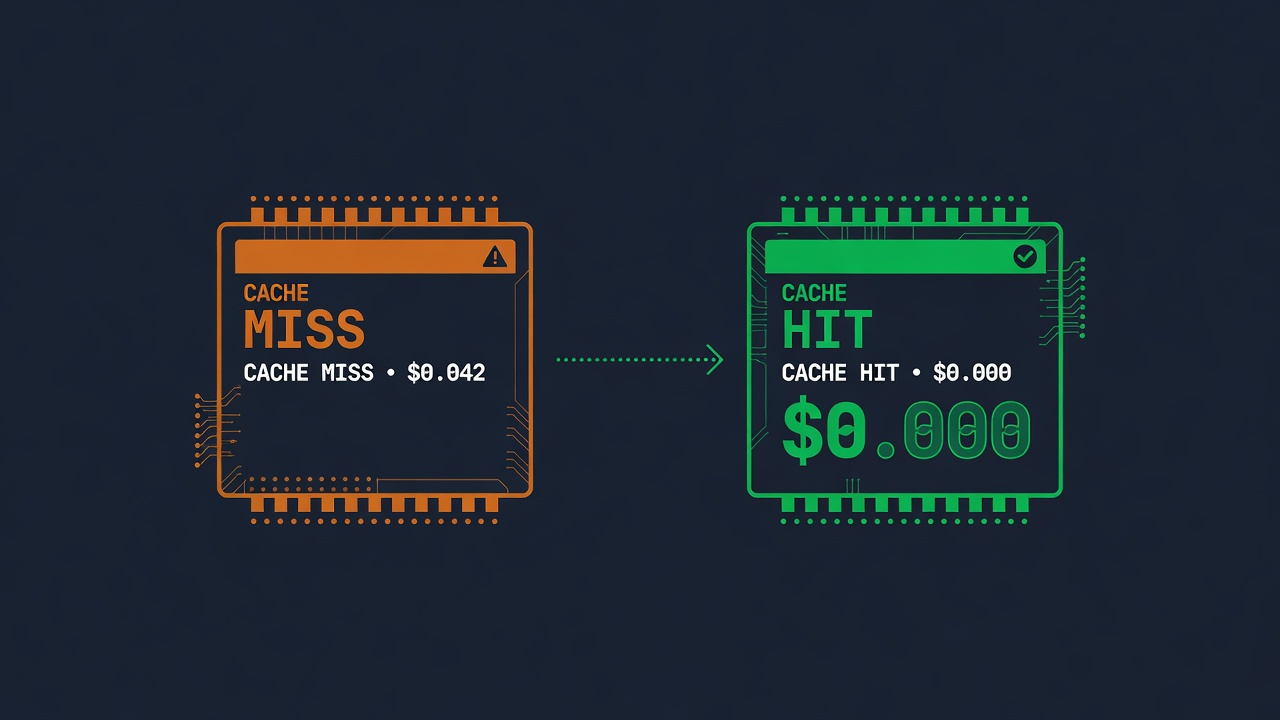
The cache sits in front of your model. Ask something it has already seen, and it returns the stored answer without calling the API at all. That call now costs $0 — not a percentage off, zero, because the request never leaves.
Exact-match caching is on by default. The interesting decision is the one most tools get wrong: semantic caching — treating "close enough" prompts as a hit — is off by default.
Why off? A hardcoded similarity cutoff (the common threshold=0.95) is a documented attack surface; a 2026 paper demonstrates hijacking ~86% of responses through exactly that mechanism. Returning a confidently-wrong cached answer is worse than paying for a fresh call. So semantic reuse is opt-in, per-namespace, and uses learned per-prompt thresholds rather than one global number. Reliability is the default; the demo metric is not.
Shrink: compress 60–95%, without breaking your code
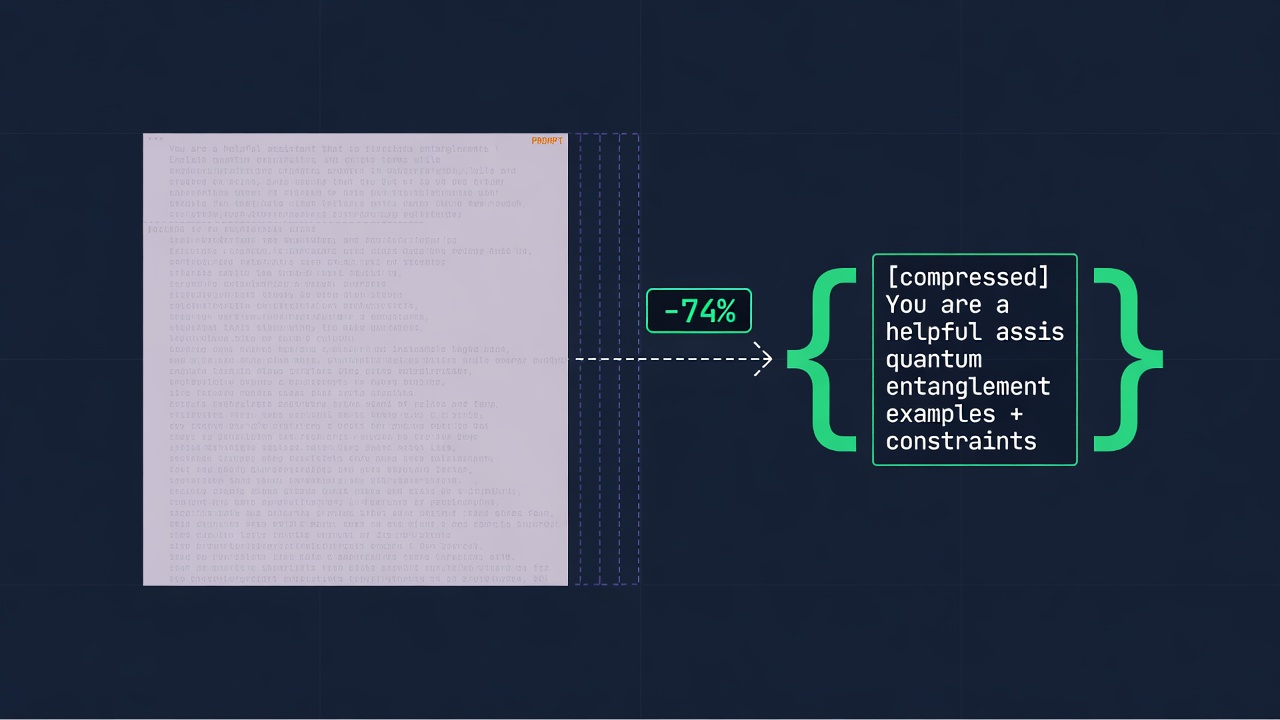
On a cache miss, the prompt gets compressed before it's forwarded — 60–95% on structured payloads. The part that matters: code and JSON are compressed extractively. Keys, signatures, and structure are never pruned, because lossy-pruning structured data quietly destroys accuracy (text-to-SQL correctness collapses under naive pruning). Prose compression (LLMLingua-2) is opt-in and warns you. And every compression is byte-exact reversible if you need the original back.
Discount: stack on top of the provider's own cache
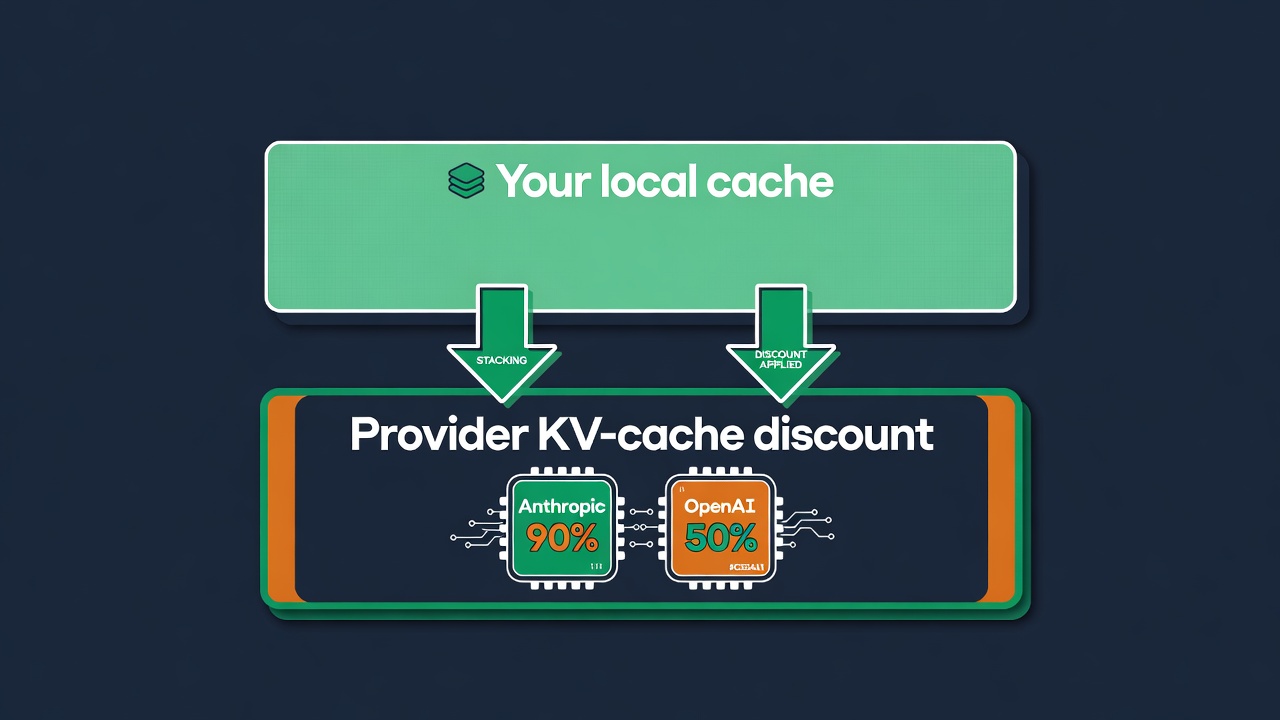
The third layer aligns your prompt prefix so the provider's native KV-cache discount actually fires — up to 90% on Anthropic, 50% on OpenAI. So even on a miss, when you do forward the call, you still pay the discounted rate. The layers stack instead of competing with the platform.
The one-line part
pip install superlocalmemory
slm wrap claude # or point any OpenAI/Anthropic/Gemini base_url at the local proxy
That's the adoption cost: change a base URL, keep your key. It's framework- and language-agnostic because it speaks the API everyone already speaks. Here's a real before/after from the proxy's own metrics — first call is a miss, the identical second call is a hit:
CACHE MISS · model called · output tokens: 596 · cost: $0.042
CACHE HIT · model skipped · output tokens: 0 · cost: $0.000
Why it's a memory engine underneath (and why that matters)
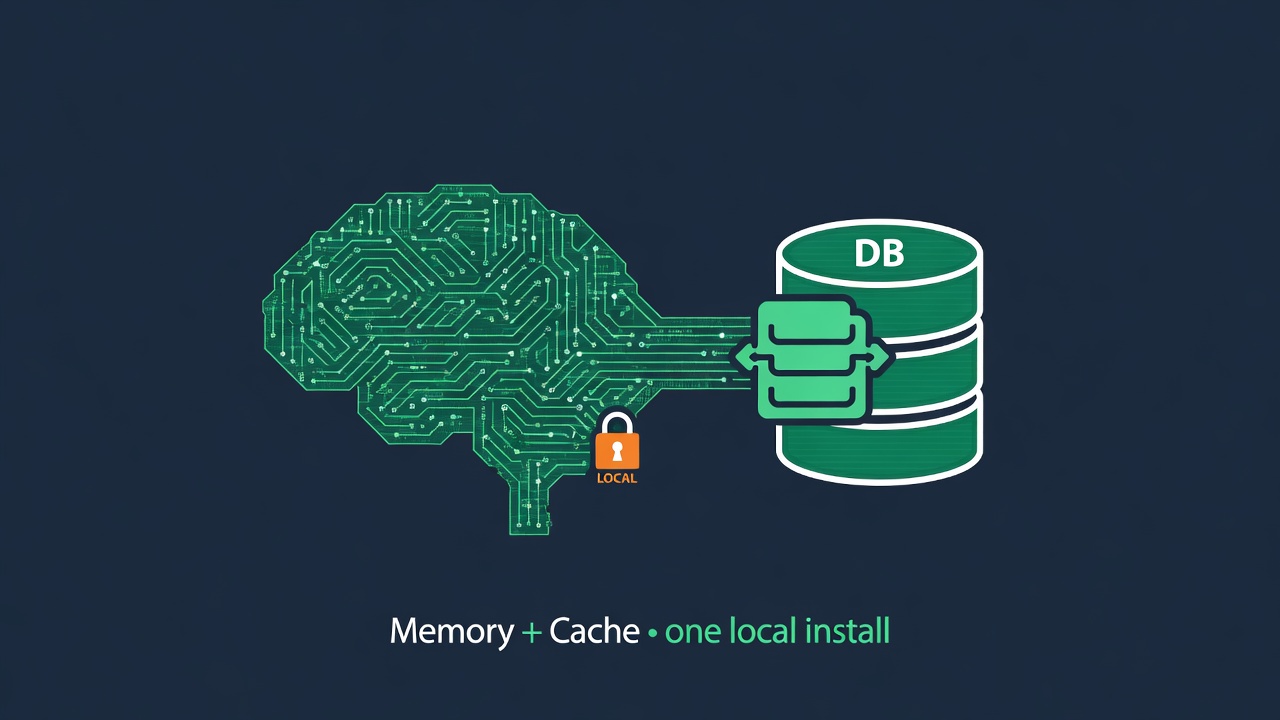
The cache isn't a standalone trick. It's the same local install as your agent's long-term memory — and that convergence is the point. Memory and cache are the two biggest costs in building an agent, and here they share one store, on your keys, on your disk. Nothing leaves the machine, which also removes a whole class of EU AI Act / GDPR exposure that a cloud proxy introduces.
The memory engine isn't a weekend project either — it's backed by three arXiv papers (2603.02240, 2603.14588, 2604.04514) covering the retrieval metric, the lifecycle dynamics, and biologically-inspired forgetting.
This is what AI Reliability Engineering looks like pointed at cost: skip what you can prove is safe to skip, shrink what you can shrink without breaking, and never trade correctness for a benchmark.
Try it
It's free and open source. If it saves you anything this week, a star genuinely helps a solo project get found.
→ github.com/qualixar/superlocalmemory